![[JPA] 인스타그램 유저 검색 N+1 문제](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdswrXJ%2FbtsGhG1aZ34%2FAAAAAAAAAAAAAAAAAAAAABpBrFxGMTJcdOPYFoysdBWacSu8Z5VuqS4TlMAj7peK%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DIXhTJdclQWyOuADhDc8bFV9CSXo%253D)

이번 포스팅으로는 프로젝트 개발 도중 직면한 N+1문제에 대한 해결과정에 대해 나열해보려 합니다.
테스트는 포스트맨을 활용하였고, 추후 JMETER를 활용하여 API 성능 테스트까지 진행해보려 합니다.
기본적으로 현재 프로젝트는 팔로우 서비스를 제공하고 있습니다.
유저 검색 API 스펙으로는 인스타그램의 검색기능과 비슷합니다.
다음은 이번 문제의 주춧돌 API에 대한 요구사항입니다.

위 이미지는 인스타그램에서 h라는 키워드로 검색을 했을 때의 결과입니다.
h에 해당하는 유저를 검색함과 동시에 현재 로그인 한 유저의 팔로우들 중 얼마나 해당 유저를 팔로우하고 있는지 한명의 유저 이름과 함께 totalCount를 응답으로 주고 있습니다.
다음은 이번 서비스에 적용시킬 API 로직 요구사항입니다.
- 유저의 이름을 기반으로 검색을 진행
- LIKE “%user_name%”
페이징을 적용한 검색 결과로는 다음과 같습니다.

content에 들어가는 응답 DTO는 다음과 같습니다.
public class UserListDto {
private Long followCnt;
private String duplicateFollower;
private Long id;
private String userName;
private int growth_point;
private int solved_cnt;
}
- id : 검색된 유저의 PK값
- userName : 검색된 유저의 이름
- followCnt : 현재 로그인한 유저의 팔로우들 중 검색된 유저를 같이 팔로우하고 있는 유저의 수
- duplicateFollower : 동시에 팔로우하고 있는 유저 중 대표 한 사람의 이름
- 위와 같은 결과를 얻기 위해서는 다음의 정보들이 필요합니다.
- 현재 로그인 한 유저의 팔로잉 리스트
- 검색된 유저들의 팔로워 리스트
- 위와 같은 결과를 얻기 위해서는 다음의 정보들이 필요합니다.
- growth_point 및 solved_cnt는 부가정보로써 크게 신경 안써도 될 것 같습니다.
Entity
User Entity
@Entity
@Getter
@Setter
@NoArgsConstructor
@Table(name = "member")
public class User implements UserDetails {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long id;
@Column(name = "user_name", unique = true)
private String userName;
@Column(name = "create_date", nullable = false, updatable = false)
private LocalDateTime createDate = LocalDateTime.now();
@Column(name = "solved_cnt", nullable = false)
private int solvedCnt = 0;
@Column(name = "bottle", nullable = false)
private int bottle = 0;
@Column(name = "growth_point", nullable = false)
private int growthPoint = 0;
@Transient
private int cnt;
// 팔로우 테이블 연관
// 사용자가 팔로우하는 관계
@OneToMany(mappedBy = "follower", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Follow> followerList = new ArrayList<>();
// 사용자를 팔로우하는 관계
@OneToMany(mappedBy = "following", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Follow> followingList = new ArrayList<>();
}
cnt 필드의 경우 비즈니스 로직에서 검색된 유저의 팔로워들 중 현재 로그인한 유저의 팔로우들이 얼마나 같이 팔로우하고 있는지 개수를 카운팅하기 위한 임시필드로써 Transient 어노테이션으로 감싸주었습니다.
Follow Entity
@Entity
@NoArgsConstructor
@Getter
@Table(
name="Follow",
uniqueConstraints = {
@UniqueConstraint(
name = "follow_follower_unique",
columnNames = {
"follower_id",
"following_id"
}
)
}
)
public class Follow {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "follow_id")
private Long id;
// 연관관계
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "follower_id")
private User follower;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "following_id")
private User following;
@Transient
private boolean isFollow;
@Builder
public Follow(User follower, User following, boolean isFollow) {
this.follower = follower;
this.following = following;
}
public void setFollow(boolean follow) {
isFollow = follow;
}
}
Follow Entity의 경우 "follower_id", "following_id" 두 개의 컬럼을 유니크 제약조건을 통해 중복 값이 들어가지 않도록 했습니다.
또한 각각의 follower, following 필드에는 LAZY를 설정해주었습니다.
다음은 시도했던 방법들 및 발생한 N+1문제에 대한 성능 테스트 결과입니다.
Attempt 1. Spring Data JPA
- 현재 로그인 한 유저의 팔로잉 리스트를 조회합니다.
- 요청변수로 들어온 키워드값을 통해 유저 검색을 진행합니다.
- 검색된 유저의 팔로워 리스트 중 현재 로그인 한 유저의 팔로잉 리스트와 겹치는 사람이 있는지 확인합니다.
- 마지막으로 겹치는 유저 중 대표 닉네임을 조회합니다.
Controller
@RestController
@RequiredArgsConstructor
@Slf4j
public class TestController {
private final UserService userService;
@GetMapping("/search")
public ResponseEntity<?> getUserList(@AuthenticationPrincipal UserDetails userDetails, @RequestParam String userName) {
//토큰에서 현재 로그인 한 유저의 ID값을 조회
List<UserListDto> response = userService.getUserList(
Long.valueOf(userDetails.getUsername()), userName);
return ResponseEntity.ok(response);
}
}
ServiceImpl
@Service
@RequiredArgsConstructor
@Slf4j
public class UserServiceImpl implements UserService {
@Override
public List<UserListDto> getUserList(Long userId, String userName) {
/**
* Process 1. 현재 로그인 한 유저의 팔로잉 리스트를 조회합니다.
* **/
Optional<User> currentUser = userRepository.findById(userId);
/**
* Exception : 유저가 존재하지 않을 경우
* **/
if(currentUser.isEmpty()) {
throw new BusinessLogicException(ErrorCode.USER_NOT_FOUND);
}
/**
* Process 2. 요청변수로 들어온 키워드값을 통해 유저 검색을 진행합니다.
* **/
List<User> searchResult = userRepository.findByUserNameContaining(userName);
/**
* Process 3. 검색된 유저의 팔로워 리스트 중 현재 로그인 한 유저의 팔로잉 리스트와 겹치는 사람이 있는지 확인합니다.
* 현재 유저의 팔로잉 리스트 조회 및 검색 결과 유저의 팔로워 리스트 조회에서 N+1 문제 발생
* **/
List<UserListDto> result = new ArrayList<>();
for(User searchUser : searchResult) {
int cnt = 0;
String duplicator = "";
for(Follow current : currentUser.get().getFollowerList()) {
for(Follow search : searchUser.getFollowingList()) {
if (current.getFollowing().getId().equals(search.getFollower().getId())) {
cnt++;
duplicator = current.getFollowing().getUsername();
}
}
}
UserListDto resultUser = UserListDto.toDto(searchUser);
resultUser.setFollowCnt((long) cnt);
resultUser.setDuplicateFollower(duplicator);
result.add(resultUser);
}
return result;
}
}
결과

위 이미지를 통해 요구사항에 원하는 결과를 출력하는 것을 알 수 있습니다.
Question?
위 Service 코드를 보면 알 수 있지만 3중 for문을 돌며 LAZY로 걸린 팔로잉, 팔로워 리스트를 조회하면서 N+1 문제까지 발생할 수 있는 걸 알 수 있습니다.
현재 유저는 5명으로 조회에 빠른 시간이 걸리지만 만약 유저수가 많아지게 되면 어떻게 될지 궁금하여 더미 데이터를 넣고 테스트 해보도록 하겠습니다.
User 더미데이터는 약 36,000개 정도 넣었습니다.

포스트맨으로 조회한 결과 아래와 같이 hibernate Query가 무한으로 실행되는 걸 확인할 수 있습니다.
끝날 생각을 안하더군요...


포스트맨을 돌려놓고 한숨자고왔더니.....
Attempt 2. QueryDSL
지연로딩으로 발생하는 N+1문제를 해결하기 위한 방법으로 Native Query를 작성하는 것을 선택했습니다.
MyBatis로 개발을 해왔기에 Query작성 하는 것은 어렵지 않게 할 수 있었습니다.
처음에는 JPQL로 작성을 했지만 서브쿼리를 사용하는 것이 조금 불편했고, Alias에 관련해서 조금 적응이 안되는 부분도 있어 복잡한 쿼리를 작성하는데 도움을 주는 QueryDSL 프레임워크를 선택해서 로직을 구현했습니다.
개발 중간에 프론트엔드로부터 추가 요구사항을 받아 List형식으로 주는 것이 아닌 무한 스크롤 적용을 위해 페이징을 적용시켜달라하여 Slice 인터페이스를 활용하여 로직을 작성했습니다.
다음은 해결과정에 대한 설명입니다.
Controller
@RestController
@RequiredArgsConstructor
@Slf4j
public class TestController {
private final UserService userService;
@GetMapping("/search")
public ResponseEntity<ResultResponse> getUserList(@AuthenticationPrincipal UserDetails userDetails, @RequestParam String userName, Pageable pageable) {
SliceResponse response = userService.findByuserNameStartsWith(
Long.valueOf(userDetails.getUsername()), userName, pageable);
return ResponseEntity.ok(new ResultResponse(ResultCode.GET_USERLIST_SUCCESS, response));
}
}
- 파라미터는 Attempt 1과 동일하게 토큰을 통한 유저 ID 및 검색 키워드를 받아 서비스 메서드를 호출합니다.
- 응답객체의 Type은 SliceResponse라는 Custom객체를 통해 Slice에서 불필요한 부분을 제외한 데이터를 전달하도록 했습니다.
SliceResponse
@Data
@Schema(description = "무한 스크롤 응답 데이터")
public class SliceResponse<T> {
@Schema(description = "응답 실제 데이터의 Collection")
protected final List<T> content;
@Schema(description = "다음 조회할 페이지의 번호")
protected final int currentPage;
@Schema(description = "content 개수")
protected final int size;
@Schema(description = "첫 번째 페이지 여부")
protected final boolean first;
@Schema(description = "마지막 페이지 여부")
protected final boolean last;
public SliceResponse(Slice<T> sliceContent) {
this.content = sliceContent.getContent();
// page 번호가 1번부터 시작되도록
this.currentPage = sliceContent.getNumber() + 1;
this.size = sliceContent.getSize();
this.first = sliceContent.isFirst();
this.last = sliceContent.isLast();
}
}
기존의 Slice 구현체는 로직에서 불필요한 부분까지 전부 전달하고 있었기에 필요한 부분만을 추출하여 전달할 수 있도록 Custom Dto를 생성하였습니다.
다음은 기존 Slice의 구현체입니다.
Slice<?>
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by FernFlower decompiler)
//
package org.springframework.data.domain;
import java.util.List;
import java.util.function.Function;
import org.springframework.data.util.Streamable;
public interface Slice<T> extends Streamable<T> {
int getNumber();
int getSize();
int getNumberOfElements();
List<T> getContent();
boolean hasContent();
Sort getSort();
boolean isFirst();
boolean isLast();
boolean hasNext();
boolean hasPrevious();
default Pageable getPageable() {
return PageRequest.of(this.getNumber(), this.getSize(), this.getSort());
}
Pageable nextPageable();
Pageable previousPageable();
<U> Slice<U> map(Function<? super T, ? extends U> converter);
default Pageable nextOrLastPageable() {
return this.hasNext() ? this.nextPageable() : this.getPageable();
}
default Pageable previousOrFirstPageable() {
return this.hasPrevious() ? this.previousPageable() : this.getPageable();
}
}
ServiceImpl
@Service
@RequiredArgsConstructor
@Slf4j
public class UserServiceImpl implements UserService {
@Override
public SliceResponse findByuserNameStartsWith(Long userId, String userName, Pageable pageable) {
// Process 1. 현재 로그인한 유저의 팔로잉 리스트 조회
List<User> currentUserFollowingList = followRepository.findByFollowings(userId);
/**
* Process 2.
* Native Query의 서브쿼리 조건 생성
* condition Collection = 현재 로그인 한 유저의 팔로잉 유저들의 ID
* **/
List<Long> condition = new ArrayList<>();
if(!currentUserFollowingList.isEmpty()) {
for(int i=0; i<currentUserFollowingList.size()-1; i++) {
User user = currentUserFollowingList.get(i);
condition.add(user.getId());
}
condition.add(currentUserFollowingList.getLast().getId());
}
// Process 3. QueryDSL 조회쿼리 실행
Slice<UserListDto> result = userRepository.searchUser(condition, userName, userId, pageable);
/**
* Process 4.
* 현재 로그인 한 유저와 동시에 팔로우 하고있는 유저들 중 대표되는 한 유저의 닉네임 조회
* **/
for(UserListDto user : result) {
if(user.getFollowCnt() > 0) {
user.setDuplicateFollower(userRepository.findByCondition(condition, user.getId()));
}
}
SliceResponse resultDto = new SliceResponse(result);
return resultDto;
}
}
다음은 핵심로직에 관한 설명입니다.
- Process 1.
- 기존 방식과 동일하게 현재 로그인 한 유저의 팔로잉 리스트를 조회합니다.
- User Entity의 팔로잉 리스트는 LAZY가 걸려있으므로 해당 조회도 JPQL을 통한 Native Query를 통해 조회를 수행합니다.
- Process 2.
- 서브쿼리의 조건으로 사용될 Collection을 생성합니다.
- 앞서 조회한 팔로우들의 ID를 담는 List를 생성하는 로직입니다.
- Process 3.
- QueryDSL로 작성한 조회쿼리를 실행합니다.
- 자세한 부분은 아래에서 설명하겠습니다.
- Process 4.
- 이 부분을 엄청 고민을 많이 했는데, 여러 결과 컬럼에서 한 유저의 닉네임만을 가져올 수 있다면 한 번의 쿼리로 끝나지만 착오 끝에 어렵겠다 판단하여 추가로직으로 작성하였습니다.
- 해당 부분에 대해서 최적화 가능한 부분이 있다면 댓글로 남겨주시면 감사하겠습니다.!
followRepository.findByFollowings(userId)
public interface FollowRepository extends JpaRepository<Follow, Long> {
@Query(value = "SELECT u FROM Follow f INNER JOIN User u ON f.following.id = u.id WHERE f.follower.id = :userId")
List<User> findByFollowings(Long userId);
}
UserId를 통해 해당하는 유저의 팔로잉 리스트를 조회하는 JPQL Query입니다.
다음은 QueryDSL을 적용한 RepositoryCustomImpl입니다.
RepositoryCustomImpl
@Slf4j
public class UserRepositoryImpl implements UserRepositoryCustom {
private final JPAQueryFactory queryFactory;
public UserRepositoryImpl(EntityManager em) {
this.queryFactory = new JPAQueryFactory(em);
}
@Override
public Slice<UserListDto> searchUser(List<Long> condition, String userName, Long currentUser, Pageable pageable) {
QUser userAlias = new QUser("userAlias");
int pageSize = pageable.getPageSize();
Expression<Long> followCountSubquery = JPAExpressions
.select(userAlias.userName.count())
.from(userAlias)
.innerJoin(follow).on(userAlias.id.eq(follow.follower.id))
.where(follow.follower.id.in(condition)
.and(follow.following.id.eq(user.id)));
BooleanBuilder predicate = new BooleanBuilder();
predicate.and(user.id.ne(currentUser));
List<UserListDto> result = queryFactory
.select(Projections.fields(UserListDto.class, user.id.as("id"),
user.userName.as("userName"),
user.growthPoint.as("growthPoint"),
user.solvedCnt.as("solvedCnt"),
ExpressionUtils.as(
followCountSubquery, "followCnt"
)
))
.from(user)
.where(user.userName.likeIgnoreCase("%" + userName + "%")
.and(predicate))
.offset(pageable.getOffset())
.limit(pageSize + 1)
.orderBy(new OrderSpecifier<>(Order.DESC, followCountSubquery))
.fetch();
boolean hasNext = false;
if (result.size() > pageSize) {
result.remove(pageSize);
hasNext = true;
}
//Slice 객체 변환
Slice<UserListDto> sliceResult = new SliceImpl(result, pageable, hasNext);
return sliceResult;
}
}
Expression<Long> followCountSubquery = JPAExpressions
.select(userAlias.userName.count())
.from(userAlias)
.innerJoin(follow).on(userAlias.id.eq(follow.follower.id))
.where(follow.follower.id.in(condition)
.and(follow.following.id.eq(user.id)));
- 우선 Qtype을 활용한 userAlias라는 Qtype 객체를 생성합니다.
- SubQuery로 사용될 Expression 타입을 생성합니다.
- 로직으로는 현재 로그인 한 유저의 팔로우들이 얼마나 검색된 유저를 팔로우하는지 COUNT를 LONG Type으로 반환합니다.
BooleanBuilder predicate = new BooleanBuilder();
predicate.and(user.id.ne(currentUser));
- 현재 로그인 한 유저의 이름이 포함되어있는지 boolean값으로 반환하는 객체입니다.
- 추후 WHERE절에 사용됩니다.
List<UserListDto> result = queryFactory
.select(Projections.fields(UserListDto.class, user.id.as("id"),
user.userName.as("userName"),
user.growthPoint.as("growthPoint"),
user.solvedCnt.as("solvedCnt"),
ExpressionUtils.as(
followCountSubquery, "followCnt"
)
))
.from(user)
.where(user.userName.likeIgnoreCase("%" + userName + "%")
.and(predicate))
.offset(pageable.getOffset())
.limit(pageSize + 1)
.orderBy(new OrderSpecifier<>(Order.DESC, followCountSubquery))
.fetch();
최종적으로 완성된 쿼리입니다.
- 반환되는 결과는 Projections를 활용하여 UserListDto로 받습니다.
- SELECT절에는 위에서 선언한 Expression 서브쿼리를 사용하고 있습니다.
- 외부쿼리의 조건으로는 키워드로 검색되며 앞서 생성한 predicate를 추가로 체크합니다.
- offset과 limit는 페이징 처리입니다.
- 또한 서브쿼리의 결과인 COUNT값을 기준으로 내림차순 정렬을 하며 쿼리를 실행합니다.
boolean hasNext = false;
if (result.size() > pageSize) {
result.remove(pageSize);
hasNext = true;
}
- hasNext의 경우 Slice를 적용시킬 경우 다음 데이터의 유무를 나타냅니다.
//Slice 객체 변환
Slice<UserListDto> sliceResult = new SliceImpl(result, pageable, hasNext);
- 마지막으로 Collection 객체를 Slice로 변환하여 return합니다.
이후 Process 4의 대표 닉네임을 조회 후 세팅하여 최종적으로 SliceResponse의 형태로 반환하며 유저 검색이 완료되게 됩니다.
결과


페이징 적용이 되어 비교가 제대로 되지않을 수 있어 size를 30,000 주고 요청하였습니다.
수정사항
size를 30,000을 주었지만 위 포스트맨의 결과를 확인해보면 2000으로 되어있는걸 뒤늦게 확인하여 이유를 찾아본 결과 다음과 같은 문제가 있었습니다.

제 Controller를 보시면 알겠지만 요청 매개변수로 Pageable 객체를 받고 있습니다.
위 PageableHandlerMethodArgumentResolverSupport 클래스는 Pageable 파라미터를 해석하고 변환하는데 사용되는 기본 클래스이며, 일부분을 캡쳐하였습니다.
해당 클래스의 역할을 간단하게 설명하면 아래와 같습니다.
1. Controller의 메서드에서 Pageable 타입의 파라미터를 처리할 수 있도록 지원합니다.
2. 요청 파라미터에서 page, size, sort 정보를 추출해서 Pageable 오브젝트로 변환합니다.
3. 페이징과 정렬을 위한 기본 값을 지정할 수 있습니다.
정리해보자면 페이징 처리 시 전달되는 Pageable 오브젝트를 생성 및 변환하는 데 기반이 되는 추상 클래스라고 볼 수 있습니다.
해당 클래스의 메서드를 살펴보면 아래와 같은 메서드가 있는데 빨간색 밑줄을 보면 size가 DEFAULT_MAX_PAGE_SIZE를 넘어갈 경우 고정하는 구문이 있습니다.
해당 구문에 의해 제가 아무리 요청변수로 size를 크게 주어도 fetch size가 2000으로 고정될 수 밖에 없었다고 볼 수 있습니다...

제대로 된 테스트를 위해 다음과 같이 수정하였습니다.
jpa:
data:
web:
pageable:
default-page-size: 20
one-indexed-parameters: true
max-page-size: 30000우선 30,000만 건의 데이터를 조회 하기위해 application.yaml 파일에서 max-page-size를 30000으로 설정해주었습니다.
그 다음은 기존 테스트와 마찬가지로 PostMan을 활용하여 30,000건의 데이터를 조회해본 결과입니다.
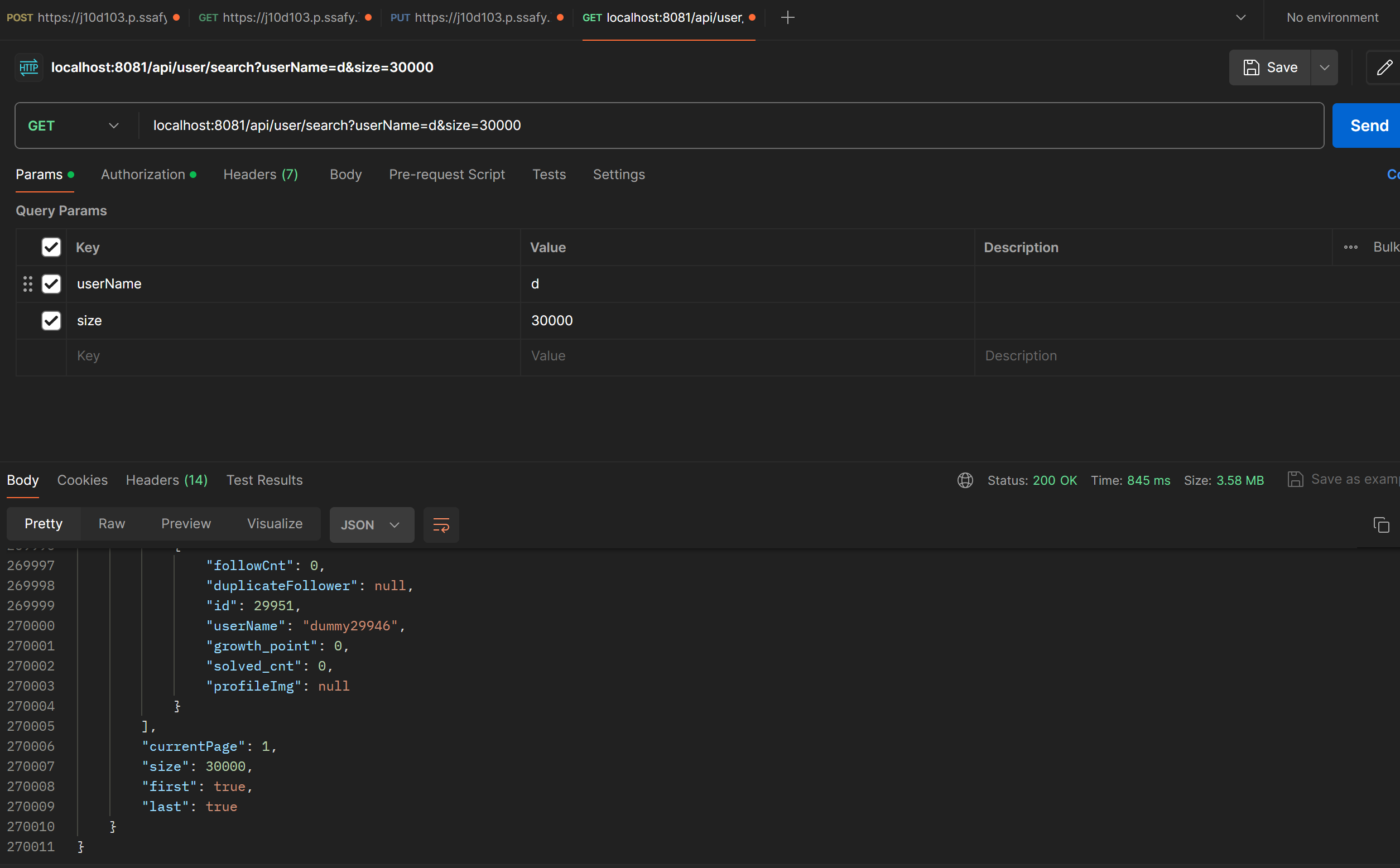
왜인지 소요시간이 더 줄어든 걸 볼 수 있네요.
제대로 된 응답시간은 다음 JMETER를 이용한 성능 테스트 포스트에서 알아볼테니 일단은 참고만 해주시면 될 것 같습니다.
SIZE는 확실히 이전 200KB에서 엄청 커진걸 확인할 수 있었습니다.
정리
지난 프로젝트까지만 해도 SQL Mapper인 MyBatis를 써서 개발을 진행했습니다.
이번 프로젝트에 참여하면서 처음으로 ORM인 JPA를 사용해보았는데, 몇 번 써보지 못했지만 ORM의 장점을 뚜렷하게 느낄 수 있었다고 생각합니다.
SQL Mapper의 단점인 컬럼의 추가로 인한 높은 노동비용 및 Query깎는 노인이 되는 듯한 느낌… 화룡점정으로 객체와 관계형 테이블 구조간 패러다임 불일치라는게 어떤건지…
하지만 ORM을 사용한다 하더라도 이번 포스팅의 내용처럼 항상 좋은 것만은 아니라는걸 확인할 수 있었습니다.
특히 N+1 문제에 대해서 직면할 수 있었죠.
객체 그래프 탐색이 유연하다는 점과 프록시 객체를 활용한 지연로딩으로 불필요한 쿼리 수행을 줄인다는 장점이 이러한 문제를 발생시킬 수 있다는 걸.
MyBatis를 활용하면서 Query실력이 향상되어서 그런지 위와 같은 문제를 해결하기 위해 Native Query로 변경하는데에는 그렇게 많은 시간이 소비되지는 않았다고 생각합니다.
(80%가 QueryDSL 적응하는 시간…)
또한 적은 데이터에서는 어떤 API도 비슷한 성능을 낼 수 있기에 간과할 수 있었던 문제지만 김영한님 강의를 수강한 수강생으로써 N+1문제가 터질 수 있겠구나 느꼈고, 바로 MySQL 프로시저를 작성하여 약 3만개의 데이터로 테스트하여 얼마나 안일한 비즈니스로직을 작성했는지 실감할 수 있었습니다…
마지막으로 제가 작성한 프로시저 코드를 마무리로 이번 포스팅을 마치도록 하겠습니다.

'Develop > Spring' 카테고리의 다른 글
| 💥 Spring 예외 처리 및 커스텀 전략 (0) | 2025.10.24 |
|---|---|
| [Springboot] 액추에이터(Actuator) (1) | 2024.04.16 |
| [JWT] 동작 원리 (Feat. Refresh Token) (0) | 2024.03.11 |
| [JWT] JSON Web Token - With JWT.io (0) | 2024.03.11 |
| [Spring] 필터 & 인터셉터 (2) | 2024.02.27 |
개발 기술 블로그, Dev
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Springboot] 액추에이터(Actuator)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FdaIbMP%2FbtsGFA0BGhB%2FAAAAAAAAAAAAAAAAAAAAAGfl43Nsldo9WhjgDoAWmDGA4QoXPBKIZgm_y5elWl1h%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DZpDfBxmmJDgLosEi0XhPF%252FaAUv0%253D)
![[JWT] 동작 원리 (Feat. Refresh Token)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FDVlV0%2FbtsFF6s31Nb%2FAAAAAAAAAAAAAAAAAAAAAG0l-4N-DoQR1cg3ejosgHZj6XmWYeDmrEgbNU241Gea%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DQcVYqqJxbT650xpKbD7UNxRnH0c%253D)
![[JWT] JSON Web Token - With JWT.io](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fcz1Trc%2FbtsFE5ueetS%2FAAAAAAAAAAAAAAAAAAAAALGrdMZTy9B2Rpd6vC7MpAzLcHpnxk82Cxcjm0ruKcU3%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DpeOTxWH1eU0f%252BtBZh9GkJ43%252BRJ8%253D)